PDF OCR mit Hazel und OCRMyPDF
02 Jan 2022Ach, die guten Vorsätze fürs neue Jahr. Ich habe endlich einen Workflow für die automatische Texterkennung von gescannten PDFs.
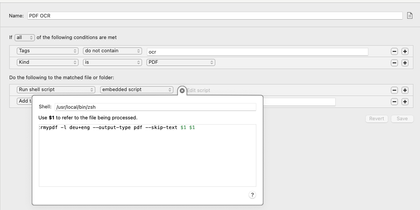
Mit Hazel werden einfach alle PDfs ohne den Tag “ocr” durch ein bash script gejagt und anschliessend der tag ans pdf gehängt.
ocrmypdf -l deu+eng --output-type pdf --skip-text $1 $1
Das script benutzt OCRMyPDF (einfach via homebrew installieren) und speichert den text direkt im gleichen PDF ab.
In Hazel sieht das dann so aus: